Overview
Artemis Search is built on several interconnected components that work together to provide powerful, reasoning-based searches. The following diagram illustrates how these components relate to each other:Artemis Search Component Relationship
Artemis Search Component Relationship
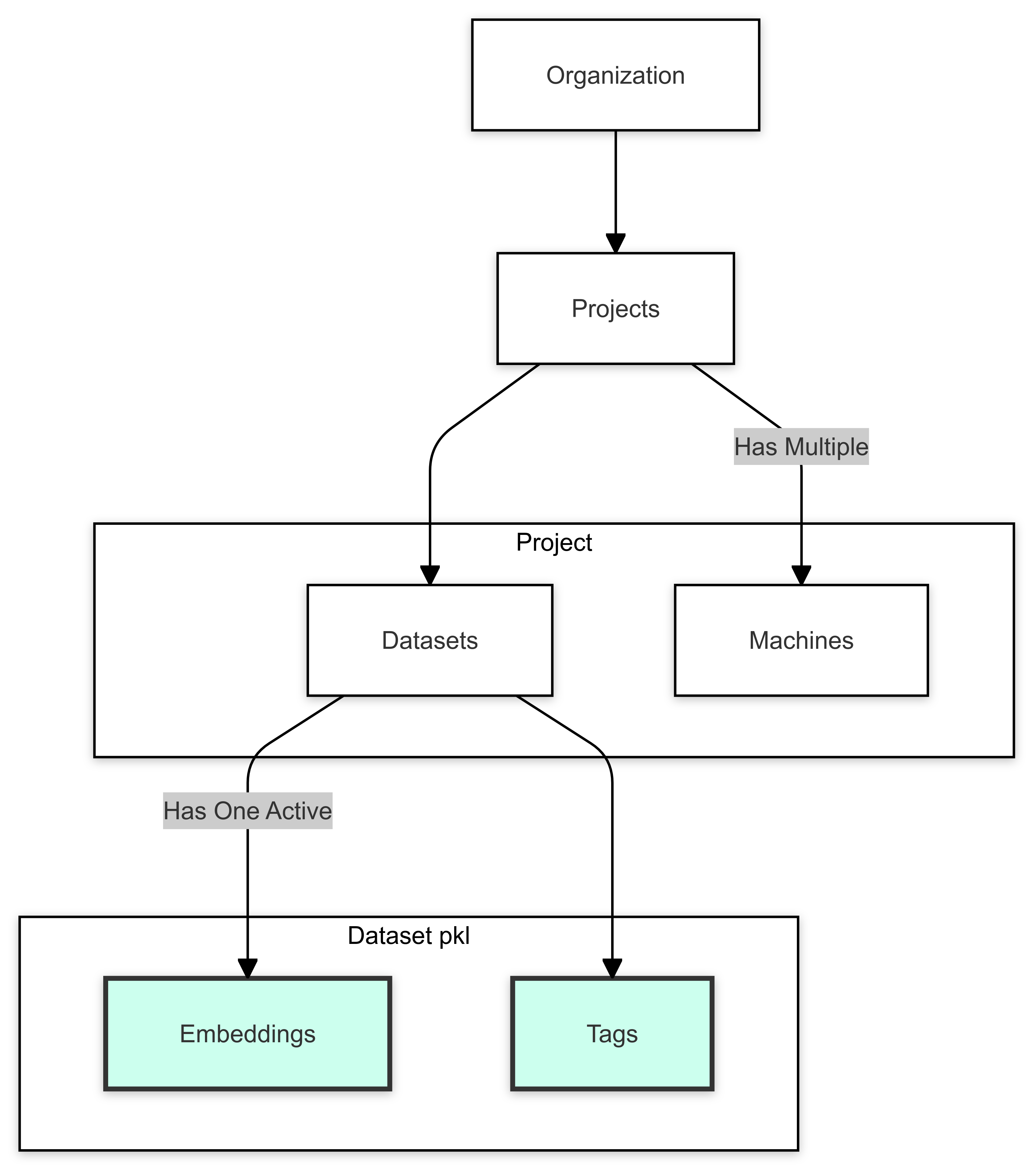
- Organizations consist of projects.
- Each project serves a particular search task. Each project may have multiple datasets but only one can be active at a time. Further, each project has dedicated machines to process search requests.
- Datasets are two-column Pandas dataframes saved as parquet files with two columns (
embeddingandtags), and only one at a time may be activated. - Machines are cloud servers which process the search requests on the active dataset. These are automatically load balanced.
Intelligent Search
What makes our search 'intelligent'?
What makes our search 'intelligent'?
Artemis Search goes beyond traditional keyword matching or semantic similarity. Our technology uses task-specialized ML ranking models to enable us to bake “reasoning” and “context” into searches.For example, when searching for “companies that require HIPAA compliance”, our system doesn’t just find companies related to medicine or HIPAA compliance. It actually reasons about which companies would be subject to HIPAA regulations based on their descriptions and activities.
Projects
Projects are the top-level entities in Artemis Search. Each project is dedicated to a particular search task.What defines a project?
What defines a project?
A project consists of:
- A unique name and description
- One or more datasets (each a pandas DataFrame saved as a parquet file with embeddings and tags columns)
- One or more machines
- Configuration settings (e.g., model type)
Datasets
Datasets are the foundation of your searches. They contain the information that Artemis Search will process and query.What's in a dataset?
What's in a dataset?
Each dataset is a pandas DataFrame saved as a parquet file with two essential columns:
embedding: Contains OpenAI text-large-3 embeddings of the text you want to search through.tag: Contains string values associated with each embedding, which will be returned as the content associated with each search result.
Machines
Machines are the computational resources that power your searches.How do machines work?
How do machines work?
Each machine runs our ML model on the active dataset when responding to search requests.
- You can have multiple machines per project for load balancing.
- At least one machine must be assigned to a project for it to be active.
- Requests are automatically load-balanced among available machines.
Playground
The playground is where you can experiment with and fine-tune your searches. Under the hood, it uses the API to perform searches.What can you do in the playground?
What can you do in the playground?
In the playground, you can:
- Select which project to experiment with
- Adjust search parameters like synthetic dataset size, probability threshold, and top-K threshold
- Enter search queries
- View and analyze search results in real-time
Search Parameters
What parameters can you adjust?
What parameters can you adjust?
- Synthetic Dataset Size: Controls how much synthetic data is generated for each search request. This parameter must be between 10 and 70. Tuning this parameter allows you to balance between search accuracy and performance.
- Probability Threshold: Filters results to keep only those above a certain probability of matching the search query. This parameter must be between 0 and 1. Tuning this parameter truncates results but does not affect search time.
- Top-K Threshold: Limits the number of top results returned. This parameter must be between 1 and Infinity. Tuning this parameter truncates results but does not affect search time.
API Integration
Artemis Search provides a RESTful API for seamless integration with your applications.How to use the API?
How to use the API?
- Each organization has its own API key for authentication.
- The main endpoint is
/search, which accepts parameters likesearch_query,num_batches,top_k,filter_query, andproject_id. - API requests must include your API token in the Authorization header.